

Table of Contents
Background
Paper link: https://arxiv.org/abs/1907.11692
Paper code: https://github.com/pytorch/fairseq
Introduction
Mô hình RoBERTa (A Robustly Optimized BERT) là phiên bản cải tiến của BERT (A Robustly Optimized BERT). So với BERT, về quy mô mô hình, khả năng tính toán và dữ liệu, đã có những cải tiến sau:
- Thông số mô hình lớn hơn (dựa trên thời gian huấn luyện được cung cấp trong bài báo, mô hình sử dụng 1024 GPU V100 để huấn luyện trong thời gian 1 ngày).
- Kích thước Batch size lớn hơn. ReBERTa sử dụng kích thước batch size lớn hơn trong quá trình đào tạo, đã thử với kích thước batch từ 256 đến 8000.
- Nhiều training data hơn (bao gồm 160GB plain text CC-NEWS. Trước đó BERT sử dụng 16GB dataset BookCorpus và Wikipedia tiếng Anh để training).
Ngoài ra, RoBERTa còn có những cải tiến về phương pháp training như sau:
- Loại bỏ dự đoán câu tiếp theo (Next Sentence Prediction – NSP).
- Mặt nạ động (Dynamic Masking): BERT dựa trên masking ngẫu nhiên (randomly masking) và dự đoán token (predicting tokens). Khi triển khai nguyên bản BERT, trong quá trình tiền xử lý dữ liệu, kết quả sẽ thu được một static mask. Trong khi đó RoBERTa sử dụng dynamic mask, mỗi khi một sequence được đưa vào mô hình thì một mẫu mặt nạ (masking pattern) mới sẽ được tạo ra [1]Chi tiết: tham khảo phần 4.1 trong bài báo. Bằng cách này, trong quá trình nhập liên tục một lượng lớn dữ liệu, mô hình sẽ dần thích ứng với các chiến lược masking khác nhau, và học được cách biểu diễn ngôn ngữ khác nhau.
- Mã hóa văn bản (text encoding): Byte-Pair Encoding (BPE) là sự kết hợp giữa các biểu diễn cấp độ ký tự và cấp độ từ, đồng thời hỗ trợ xử lý nhiều từ thông dụng trong kho dữ liệu ngôn ngữ tự nhiên. Hiện thực nguyên bản BERT sử dụng từ vựng BPE cấp độ ký tự với kích thước 30K, được học sau khi xử lý trước đầu vào bằng quy tắc mã hóa heuristic (heuristic tokenization rule). Các nhà nghiên cứu của Facebook đã không áp dụng phương pháp này, nhưng đã cân nhắc sử dụng từ vựng BPE cấp byte lớn hơn để đào tạo BERT. Từ vựng này 50K đơn vị subword, mà không cần bất kỳ xử lý trước hoặc mã hóa (tokenization) đầu vào nào [2]Chi tiết: tham khảo phần 4.4 trong bài báo.
RoBERTa được kiến lập dựa trên chiến lược che dấu ngôn ngữ của BERT vả sửa đổi các siêu tham số chính trong BERT, bao gồm xóa mục tiêu đào tạo câu tiếp theo của BERT, đồng thời sử dụng batch size lớn hơn và tốc độ huấn luyện lớn hơn để đào tạo. RoBERTa cũng cấp nhận tham số huấn luyện đầu vào nhiều hơn BERT, thời gian diễn ra lâu hơn. Điều này cho phép RoBERTa có khả năng tổng quát hóa các tác vụ hạ nguồn (downstream tasks) tốt hơn so với BERT.
Trải qua thời gian training dài, mô hình trong bài báo này đã được 88.5 điểm trên bảng xếp hạng GLUE, tương đương với 88.4 điểm được báo cáo bởi Yang và cộng sự (2019). Mô hình trong bài báo này đã đạt được state-of-the-art cho 4 trên 9 nhiệm vụ của GLUE: MNLI, QNLI, RTE và STS-B [3]Chi tiết: tham khảo phần 1 trong bài báo. Ngoài ra, RoBERTa cũng đạt điểm cao nhất trong bảng xếp hạng của SQuAD [4]Chi tiết: tham khảo phần 5.2 trong bài báo và RACE [5]Chi tiết: tham khảo phần 5.3 trong bài báo.
Tóm lại, những đóng góp của bài viết này là:
- Đề xuất một tập hợp các lựa chọn thiết kế BERT quan trọng và các chiến lược đào tạo, đồng thời đưa ra các giải pháp thay thế có thể cải thiện việc thực hiện các downstream tasks.
- Sử dụng dataset mới CCNEWS, và xác nhận rằng việc sử dụng nhiều dữ liệu hơn để pre-training có thể cải thiện hơn nữa hiệu suất của downstream tasks.
- Cải tiến training trong bài báo này chỉ ra rằng, dưới sự lựa chọn thiết kế chính xác, pre-training cho masked language model có tính cạnh tranh cao hơn tất cả các phương pháp được công bố gần đây. Đồng thời, mô hình, pre-training và fine-tuning code đã được implemented trong bản released mới nhất của PyTorch.
Background
<Giới thiệu sơ lược về BERT>.
Experimental setup
Configuration
Sử dụng FAIRSEQ để tái hiện BERT, nhưng đã thay đổi peak learning rate và số bước warmup, điều chỉnh giá trị theo các cài đặt khác nhau và các siêu tham số khác với BERT nguyên gốc.
Tác giả nhận thấy rằng mô hình nhạy cảm với hệ số ε của Adam trong quá trình huấn luyện, và đôi khi nó có thể đạt được độ ổn định tốt hơn bằng cách điều chỉnh hệ số. Khi đào tạo với quy mô lớn hơn, việc đặt hệ số kỳ hạn thường xuyên \(β_2=0.98\) cũng có thể cải thiện độ ổn định của mô hình.
Data
RoBERTa sử dụng 160GB training text, vượt xa 16GB của BERT, trong đó bao gồm:
- BookCorpus và English Wikipedia: Bộ training set nguyên thủy của BERT, kích thước 16GB.
- CC-NEWS: gồm 63 triệu bản tin tiếng Anh được thu thập từ tháng 9/2016 đến tháng 2/2019, kích thước 76GB (sau khi lọc).
- OpenWebText: nội dung web trích xuất từ URL được chia sẻ trên Reddit (ít nhất 3 lượt likes), dung lượng 38GB.
- Stories: Một tập con của dataset CommonCrawl, chứa kiểu câu chuyện của chế độ Winograd, dung lượng 31GB.
Evaluation
Sử dụng ba tiêu chuẩn sau để đánh giá các pre-trained model cho các downstream tasks:
- Tiêu chuẩn đánh giá hiểu biết ngôn ngữ chung (The General Language Understanding Evaluation – GLUE), là tập hợp của 9 bộ dữ liệu được sử dụng để đánh giá các hệ thống hiểu ngôn ngữ tự nhiên.
- Tập dữ liệu trả lời câu hỏi SQuAD Stanford (The Stanford Question Answering Dataset – SQuAD), cung cấp thông tin cơ bản và câu hỏi. Nhiệm vụ là trả lời câu hỏi bằng cách trích xuất relevant span từ ngữ cảnh.
- Nhiệm vụ Tìm hiểu lại của kỳ thi RACE (The ReAding Comprehension from Examinations – RACE), là một tập dữ liệu đọc hiểu lớn, với hơn 28,000 đoạn văn và gần 100,000 câu hỏi. Bộ dữ liệu này lấy từ bài kiểm tra tiếng Anh ở Trung Quốc và được thiết kế cho học sinh trung học cơ sở và trung học phổ thông.
Training Procedure Analysis
Giữ nguyên kiến trúc training của mô hình BERT, và cấu hình của nó giống với \(BERT_{base}(L=12, H=768, A=12, 110M params)\).
Static vs. Dynamic Masking
Original BERT static mask: xử lý mask được hoàn thành trong quá trình tiền xử lý dữ liệu. Để tránh tình trạng mask giống nhau cho mỗi trường hợp huấn luyện gặp phải trong mỗi epoch, dữ liệu huấn luyện được sao chép 10 bản sao và được che trong 10 phương thức mask khác nhau. Nhưng ngay cả như vậy, huấn luyện 40 epoch, cùng một phương thức mask của cùng một câu, mô hình cũng sẽ gặp 4 lần lặp liên tục trong quá trình đào tạo.
Dynamic mask: hoạt động tạo mask cho từng chuỗi được thực hiện khi chuỗi được đưa vào mô hình. Điều này rất quan trọng khi pre-training nhiều bước hơn hoặc tập dữ liệu lớn hơn.
Phân tích kết quả so sánh thực nghiệm:
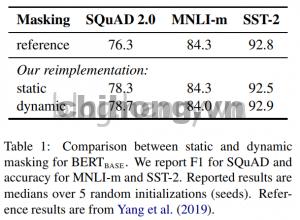

Ta thấy dynamic mask tốt hơn static mask một chút, vì vậy các thí nghiệm tiếp theo của tác giả đều sử dụng phương pháp dynamic mask.
Model Input Format and Next Sentence Prediction (NSP)
Nguyên thủy BERT có hai nhiệm vụ chính, là dự đoán từ bị masked và dự đoán câu tiếp theo. Theo quan điểm của các nghiên cứu gần đây (Lample and Conneau, 2019; Yang et al., 2019; Joshi et al., 2019) bắt đầu đặt câu hỏi về sự cần thiết của NSP, bài báo này đã thiết kế 4 phương pháp đào tạo sau:
- SEGMENT-PAIR + NSP: dữ liệu đầu vào bao gồm hai phần, mỗi phần là một phân đoạn (segment) từ cùng một tài liệu hoặc các tài liệu khác nhau (segment là nhiều câu liên tiếp). Tổng số token của hai segments này nhỏ hơn 512. Pre-training bao gồm các nhiệm vụ Masked LM (MLM) và các nhiệm vụ NSP. Đây là những gì mà BERT ban đầu đã làm.
- SENTENCE-PAIR + NSP: Dữ liệu đầu vào cũng bao gồm hai phần, một phần là một câu đơn từ cùng một tài liệu hoặc các tài liệu khác nhau, tổng số token của hai câu này nhỏ hơn 512. Vì các đầu vào này ít hơn đáng kể 512 tokens, độ lớn batch size được tăng lên để giữ cho tổng số token tương tự như SEGMENT-PAIR + NSP. Pre-training bao gồm các nhiệm vụ MLM và các nhiệm vụ NSP.
- FULL-SENTENCES: Đầu vào chỉ có một phần (thay vì hai phần), các câu liên tiếp từ cùng một tài liệu hoặc các tài liệu khác nhau; và tổng số token không vượt quá 512. Đầu vào có thể vượt qua ranh giới tài liệu. Nếu nó vượt qua tài liệu, token ranh giới tài liệu sẽ được thêm vào cuối tài liệu trước đó. Pre-training không bao gồm các nhiệm vụ NSP.
- DOC-SENTENCES: Đầu vào chỉ có một phần (chứ không phải hai phần). Cấu trúc đầu vào tương tự như FULL-SENTENCES, ngoại trừ việc nó không cần vượt qua ranh giới tài liệu. Đầu vào là các câu liên tục từ cùng một tài liệu và tổng số token không vượt quá 512. Đầu vào được lấy mẫu ở gần cuối tài liệu có thể ngắn hơn 512 tokens, vì vậy trong những trường hợp này, kích thước batch size được tăng động để đạt được tổng số token tương tự như FULL-SENTENCES. Pre-training không bao gồm các nhiệm vụ NSP.
Kết quả so sánh của 4 chế độ đào tạo trên được thể hiện trong bảng kết quả sau: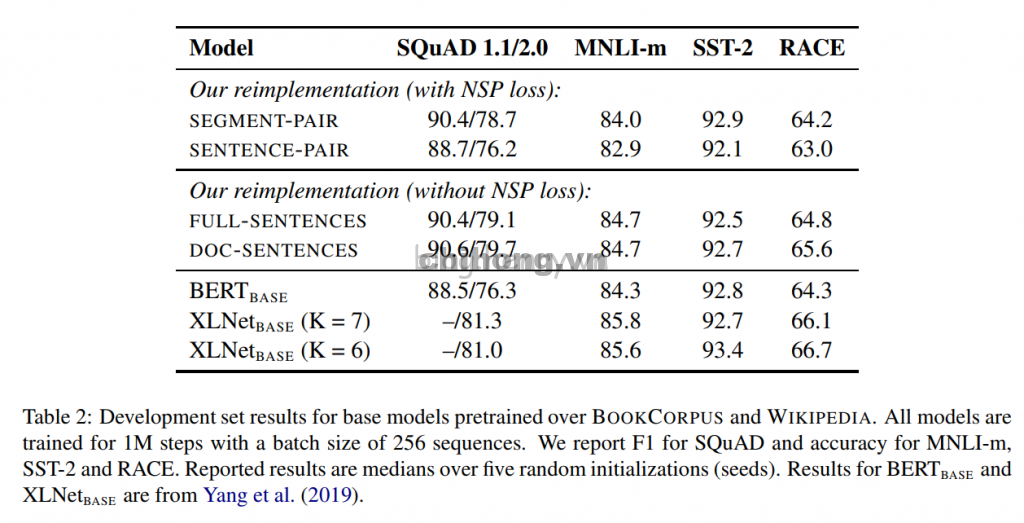

BERT sử dụng định dạng đầu vào là SEGMENT-PAIR (có thể chứa nhiều câu). Từ kết quả thực nghiệm, nếu sử dụng NSP loss thì SEGMENT-PAIR tốt hơn SENTENCE-PAIR (hai câu). Người ta thấy rằng một câu đơn lẻ sẽ gây hại cho việc thực hiện các nhiệm vụ downstream tasks, có thể khiến mô hình không thể học các phụ thuộc từ xa. So sánh tiếp theo là so sánh đào tạo không NSP loss với đào tạo các khối văn bản từ một tài liệu duy nhất (DOC-SENTENCE). Chúng ta nhận thấy rằng so với Devlin và cộng sự (2019), hiệu suất của cài đặt này tốt hơn so với kết quả BERT-base ban đầu: việc loại bỏ mất NSP có thể bằng hoặc cao hơn một chút so với BERT ban đầu trong việc thực hiện các downstream tasks. Lý do có thể do việc triển khai BERT ban đầu chỉ loại bỏ việc mất NSP, nhưng vẫn duy trì hình thức đầu vào của SEGMENT-PAIR.
Cuối cùng, thử nghiệm cũng phát hiện ra rằng hiệu suất của việc giới hạn trình tự trong một tài liệu (FULL-SENTENCES). Tuy nhiên, trong chiến lược DOC-SENTENCES, mẫu ở cuối tài liệu có thể ít hơn 512 tokens. Để đảm bảo rằng tổng số token trong mỗi batch được duy trì ở mức cao, batch size cần được điều chỉnh động. Để thuận tiện cho việc xử lý, định dạng câu đào vào DOC-SENTENCES sẽ được chấp nhận sau đó.
Training with large batches
Các nghiên cứu neural machine translation trước đây chỉ ra rằng, khi sử dụng các mini-batches để tiến hành đào tạo, việc tăng tốc học đúng cách có thể cải thiện tốc độ tối ưu hóa và hiệu suất tác vụ cuối cùng. Các nghiên cứu gần đây đã chỉ rằng BERT cũng có thể chấp nhận large batch training. Devlin và cộng sự (2019) ban đầu đào tạo BERT-base chỉ với 1 triệu bước và batch size là 256 sequences. Thông qua tích lũy gradient, 125K bước của batch size = 2K sequences, hoặc 31K bước của batch size = 8K, cả hai xấp xỉ tương đương về chi phí tính toán.
Trong bảng dưới đây, độ phức tạp (perplexity, một chỉ báo của mô hình ngôn ngữ) và hiệu suất tác vụ cuối cùng của BERT-base khi tăng kích thước batch size được so sánh. Có thể nhận thấy rằng việc đào tạo theo large batches cải thiện sự nhầm lẫn của các mục tiêu masked language modeling và độ chính xác của nhiệm vụ cuối cùng. Các large batches cũng dễ dàng hơn cho việc đào tạo song song dữ liệu phân tán. Trong các thử nghiệm tiếp theo, bài báo sử dụng kích thước batch size = 8K để đào tạo song song.
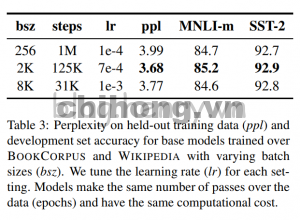
Ngoài ra, You và cộng sự (2019) thậm chí đã tăng batch size lên 32K khi training BERT. Đối với việc thăm dò giới hạn của giá trị batch size, nó còn để lại cho các nghiên cứu tiếp theo.
Text Encoding
Byte pair encoding (BPE – Sennrich và cộng sự, 2019) là sự kết hợp giữa các biểu diễn cấp độ ký tự và cấp độ từ. Lược đồ mã hóa này có thể xử lý một lượng lớn các từ thường thấy trong kho ngữ liệu ngôn ngữ tự nhiên (natural language corpus). BPE không dựa và các từ hoàn chỉnh mà dựa trên các đơn vị từ phụ (sub-word). Những đơn vị sub-word này được trích xuất thông qua phân tích thống kê của huấn luyện kho ngữ liệu (training corpus). Kích thước của từ vựng thường từ 10,000 đến 100,000. Khi mô hình hóa kho ngữ liệu lớn và đa dạng, các ký tự unicode chiếm phần lớn từ vựng. Công trình của Radford và cộng sự (2019) đã giới thiệu một BPE đơn giản nhưng hiệu quả, bằng việc sử dụng các cặp byte thay vì các ký tự unicode làm đơn vị từ khóa con.
Dưới đây tóm tắt hai phương pháp triển khai BPE:
- Dựa trên char-level: phương pháp BERT nguyên thủy, có được bằng cách lấy văn bản đầu vào theo phương pháp heuristically (heuristically stemming).
- Dựa trên bytes-level: sự khác biệt với char-level là bytes-level sử dụng byte thay vì ký tự unicode làm đơn vị cơ bản của từ phụ, vì vậy mọi văn bản đầu vào đều có thể được mã hóa mà không cần sử dụng label UNKOWN.
Khi BPE sử dụng bytes-level, kích thước từ vựng được tăng lên từ 30,000 (char-level của BERT nguyên thủy) lên 50,000. Điều này bổ sung thêm 15 triệu tham số cho BERT-base và 20 triệu tham số cho BERT-large.
Các nghiên cứu trước đây đã chỉ ra rằng cách tiếp cận này sẽ gây ra sự suy giảm hiệu suất nhẹ trong downstream tasks. Nhưng tác giả của bài báo này tin rằng những lợi thế của việc hợp nhất mã hóa này sẽ lớn hơn sự suy giảm hiệu suất nhẹ; và tác giả sẽ so sánh thêm các lược đồ encoding khác nhau trong công việc sau này.
RoBERTa
Tổng kết lại, RoBERTa sử dụng dynamic masking, FULL-SENTENCES without NSP loss, larger mini-batches và larger byte-level BPE (phương pháp mã hóa văn bản này GPT-2 cũng đã được sử dụng, và BERT đã sử dụng độ chi tiết của ký tự trước đây) để đào tạo. Ngoài ra, nó cũng bao gồm một số chi tiết, bao gồm: pre-training data lớn hơn, training steps nhiều hơn.
Để phân biệt các yếu tố này với tầm quan trọng của các lựa chọn mô hình khác (ví dụ như pre-training goals), RoBERTa đầu tiên được đào tạo theo kiến trúc BERT-large (L = 24, H = 1024, A – 16355m). như cách được Devlin và cộng sự sử dụng, bài báo này sử dụng bộ dữ liệu BOOKCORPUS và WIKIPEDIA để đào tạo trước 100k bước. Họ đã sử dụng 1024 GPU V100 để đào tạo trước mô hình trong khoảng một ngày.
Kết quả được thể hiện trong bảng dưới đây. Khi kiểm soát dữ liệu đào tạo, có thể thấy rằng RoBERTa là một cải tiến lớn so với kết quả BERT-big được báo cáo ban đầu, một lần nữa khẳng định tầm quan trọng của các lựa chọn thiết kế mà chúng ta đã thảo luận.


Table 4: Kết quả của tập phát triển RoBERTa, vì nhiều dữ liệu hơn được đào tạo trước (16GB→160GB text), và thời gian đào tạo dài hơn trước (100K→300K→500K bước), mỗi hàng tích lũy sự cải thiện của các hàng trên. RoBERTa tuân thủ kiến trúc và mục tiêu đào tạo của BERTLARGE.
Kết quả trên GLUE: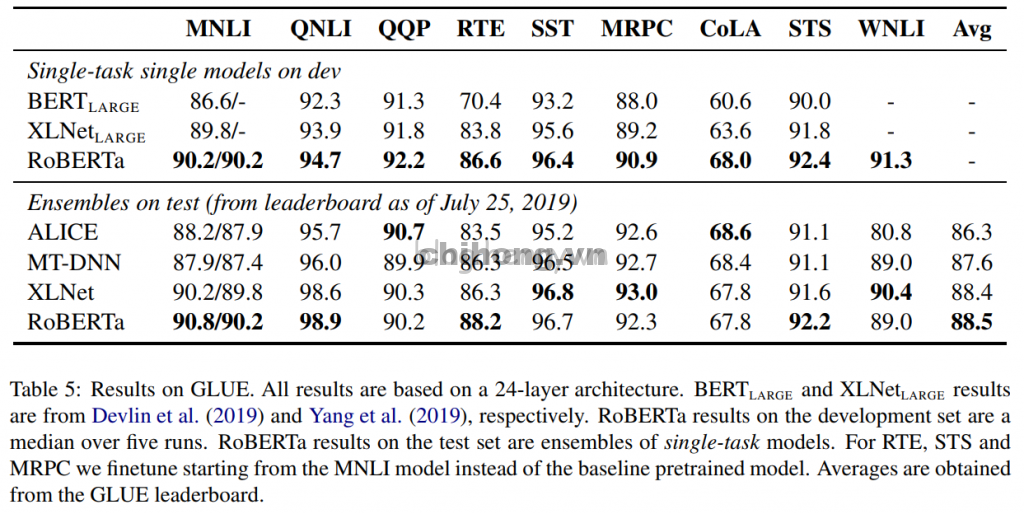

Table 5: Kết quả của GLUE. Tất cả các kết quả đều dựa trên kiến trúc 24 lớp. Kết quả của RoBERTa trên tập phát triển là trung bình của 5 lần chạy. Kết quả của RoBERTa trên tập thử nghiệm là một tập hợp các mô hình nhiệm vụ đơn lẻ. Đối với RTE, STS và MRPC, hãy bắt đầu với mô hình MNLI thay vì mô hình cơ sở được đào tạo trước. Mức trung bình có thể nhận được từ bảng xếp hạng GLUE.
Kết quả trên SQuAD:
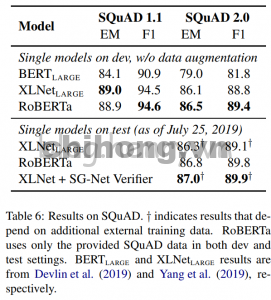

Table 6: Kết quả của SQuAD. † chỉ ra rằng nó phụ thuộc vào kết quả của các dữ liệu đào tạo bên ngoài khác. RoBERTa chỉ sử dụng dữ liệu SQuAD được cung cấp trong cài đặt phát triển và thử nghiệm.
Kết quả trên RACE:
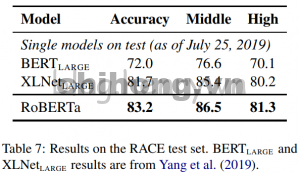

Conclusion
Khi pre-training mô hình BERT, bài viết này đánh giá một cách cẩn thận một số quyết định khi thiết kế. Người ta thấy rằng bằng cách đào tạo mô hình trong thời gian dài hơn và xử lý nhiều dữ liệu hơn, hiệu suất của mô hình có thể được cải thiện đáng kể; xóa bỏ NSP; đào tạo một sequence dài hơn; và tự động thay đổi masking mode được áp dụng vào dữ liệu đào tạo. Đề án cải tiến trước khi đào tạo nói trên là RoBERTa đề xuất trong bài viết này, đã đạt kết quả tốt nhất hiện nay trên GLUE, RACE và SQuAD. Lưu ý: không có tinh chỉnh đa nhiệm trên GLUE và không có dữ liệu bổ sung nào được sử dụng trên SQuAD. Những kết quả này minh họa tầm quan trọng của những quyết định thiết kế bị bỏ qua trước đây và cho thấy rằng mục tiêu pre-training của BERT vẫn mang tính cạnh tranh so với các lựa chọn thay thế được đề xuất gần đây.
